Training vs. testing data in machine learning


Potential issues in machine learning design聽
Machine learning (ML) is a subset of artificial intelligence (AI) that involves using algorithms and statistical models to enable computer systems to learn from data and improve performance on a specific task over time, without being explicitly programmed. It involves feeding large amounts of data into algorithms that automatically learn patterns in the data. ML has a wide range of applications, and it is rapidly changing the way we interact with technology and solve complex problems.
Despite their widespread use, ML algorithms can encounter a variety of classic problems that can impact their performance and accuracy. Several scandals made headlines about inadequate, biased training data or test data. The scandals of the Dutch tax office, Volkswagen鈥檚 鈥淒ieselgate鈥?and Amazon's hiring software serve as a strong reminder of the disastrous consequences that can result from the use of automated systems without appropriate safeguards, especially as governments and corporations worldwide are increasingly relying on algorithms and AI to streamline their processes.
There are several instances where ML algorithms can go wrong, but in the best scenario, those mistakes are identified within the process of design of the algorithm. Overfitting, underfitting and feature-selection biases are common issues while composing an ML algorithm. Overfitting occurs when a model learns the noise in the training data and does not generalize well to new data. Underfitting means that a model is too simple to capture the underlying patterns in the data. And feature-selection biases appear when a model is built using a subset of features that are chosen based on their performance on the training data and may not generalize well to new data.
ML algorithms can also be sensitive to outliers and imbalanced or outdated training and test datasets. Addressing these classic problems is essential for creating accurate and reliable ML models that can provide valuable insights and predictions.
How are ML algorithms created
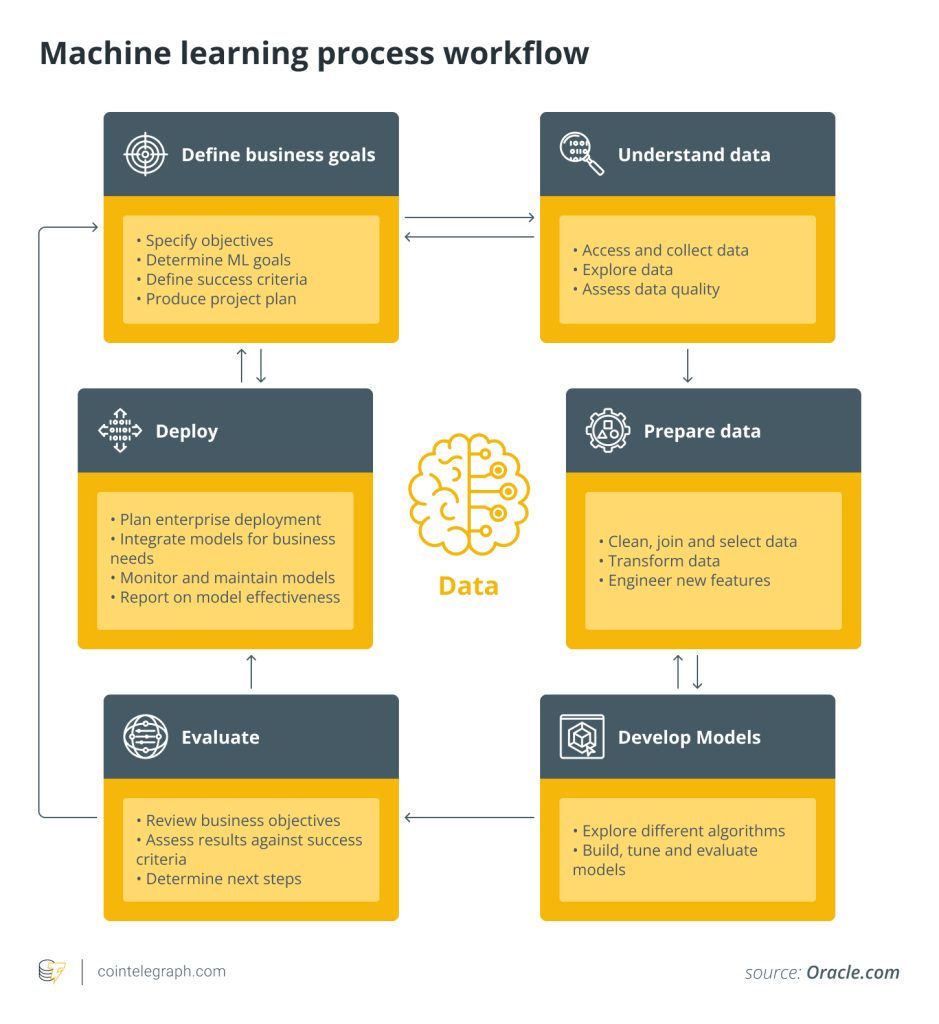
Although ML is mostly the center of attention, it is hard to understand the birth of those algorithms without discovering the process around their creation. Usually, data scientists are responsible for the creation of ML algorithms. Data science is a multidisciplinary field that combines statistical, mathematical and computational tools to extract insights and knowledge from data. Data science is a broader term that includes a variety of techniques and approaches for working with data. ML is a subset of those techniques and focuses specifically on building algorithms and models.

The steps typically include defining the problem, collecting and cleaning the data, exploring the data, developing a model based on a hypothesis, testing and validating the model, and communicating the results to stakeholders. Throughout the process, data scientists use a variety of tools and techniques 鈥?including statistical analysis, ML and data visualization 鈥?to extract and communicate meaningful insights and identify patterns in the data.
The steps are not set in stone. They are also strongly dependent on the field of application. For example, in the academic environment, the model evaluation is followed by communication and dissemination of the results. In production, meanwhile, the evaluation is followed by deployment, monitoring and maintenance. In a business environment, it鈥檚 hardly ever a linear process and is instead a series of reiterations.
ML plays an important role in the step of modeling. Modeling refers to the process of building a mathematical representation of a real-world system or phenomenon using data. The goal of modeling is to learn patterns, relationships and trends in the data. Modeling typically involves selecting an appropriate algorithm and its relevant features and tuning the model鈥檚 hyperparameters. The performance of the model is evaluated using various metrics, and the model is refined iteratively until satisfactory performance is achieved.聽
Steps involved in ML model selection
The steps of the data science life cycle are also often mentioned as parts of ML since they are unavoidable for building an ML algorithm. However, modeling itself also includes sub-steps, such as feature engineering, splitting the data, selecting the model, tuning the hyperparameters and evaluating the model. Model selection is not purely based on a question that needs to be answered but also on the nature of the available data. Certain characteristics are important in model selection, such as the number of features, the presence of categorical or numerical variables, and the data distribution. Some algorithms might work better with specific data types or distributions.
Proper data preprocessing and explanatory data analytics are crucial for any statistical modeling because experts discover the characteristics through such steps. They provide the necessary information to choose between the appropriate algorithms as well. There are two main types of algorithms in ML: supervised and unsupervised. In supervised ML, models are trained on labeled data, while in unsupervised, models learn patterns from unlabeled data. See below a few examples of ML models.


Semi-supervised ML is a type of ML where a model learns from both labeled and unlabeled data. In contrast to supervised learning, where the model is trained solely on labeled data, semi-supervised learning takes advantage of the additional information available in the form of unlabeled data to improve model accuracy.聽
They are widely used in complex ML models. For example, deep learning models can benefit from semi-supervised learning by incorporating both labeled and unlabeled data into the training process. This can help to improve model performance, especially when the amount of labeled data is limited.
What is training data in machine learning
In ML, a model is developed to learn patterns or make predictions based on data. To create an effective model and evaluate its performance, the available data is typically split into three separate sets: training, validation and test sets. The training set is the largest portion of the data and is used to train the model. A validation set is a subset of data used to tune the hyperparameters of a model during training. And the test set is a separate subset of data used to evaluate the final performance of the model after tuning.
The function of training data is different based on the type of model. In supervised learning, the training data consists of input-output pairs, also known as features and labels. Features are the input variables used to make predictions, while labels are the corresponding output variables that the model is trying to predict. The goal of supervised learning is to learn a mapping from input features to output labels so the model can make accurate predictions on new, unseen data.

For example, in a blockchain-related classification task, the features could be transaction attributes such as the sender and receiver addresses, transaction amount, and transaction fees, while the label would be whether the transaction is fraudulent (1) or not fraudulent (0).聽
The training data would consist of a collection of historical transactions from the blockchain network with their corresponding fraudulent or not fraudulent labels. The supervised learning algorithm would then learn patterns and associations between the transaction attributes and their fraudulent or not fraudulent labels to predict and identify potentially fraudulent transactions.
In unsupervised learning, the training data consists of input features only, without any corresponding labels. The goal of unsupervised learning is to discover underlying patterns, structures or relationships within the data, without any guidance from output labels. Unsupervised learning algorithms are typically used for tasks such as clustering, dimensionality reduction and anomaly detection.
Clustering is the process of grouping similar data points into clusters based on their inherent patterns. Dimensionality reduction aims to reduce the number of features in a dataset without losing significant information. Anomaly detection identifies rare or abnormal data points that deviate significantly from the norm.
Staying with the previous example, unsupervised ML could help in the classification of fraudulent activities by discovering underlying patterns, relationships or clusters within the transaction data. The role of training data in this context is to provide the algorithm with a large set of unlabeled transactions containing only features such as sender and receiver addresses, transaction amounts, transaction fees and network activity.
The unsupervised algorithm then analyzes these features and groups transactions based on their similarity, potentially revealing clusters of transactions that share common characteristics. By studying these clusters, analysts can gain insights into unknown or emerging fraudulent behaviors.
Validation data and hyperparameter tuning
The validation set is a smaller portion of the data that is not used during the training phase. It is used to fine-tune the model鈥檚 hyperparameters, which are not directly optimized during the training process.
Hyperparameter tuning is the process of selecting the best combination of hyperparameters for an ML algorithm that produces the best possible model performance on a given task. Hyperparameters differ by model, but tuning typically involves defining the range of hyperparameters, training and evaluating the model for each combination, and selecting the best-performing model.

In supervised ML, hyperparameters are parameters that are set before training the model, such as the learning rate, number of decision trees, maximum depth, etc., in the given example of a gradient boost decision tree. In unsupervised ML, hyperparameters may include the number of clusters in a clustering algorithm and the number of principal components to retain in principal component analysis.
Model validation is an essential step in hyperparameter tuning. The goal of model validation is to estimate the model鈥檚 ability to generalize to new, unseen data. Overfitting occurs when a model learns the noise in the training data and fails to generalize to new data. Underfitting occurs when a model is too simple and cannot capture the underlying patterns in the data. The bias-variance tradeoff is a critical concept in ML that relates to overfitting and underfitting.
A model鈥檚 bias measures how much the model鈥檚 predictions differ from the true values, while variance measures how much the model's predictions vary across different training sets. A high-bias model is typically too simple and may underfit the data, while a high-variance model is typically too complex and may overfit the data. The goal is to find the sweet spot between bias and variance that produces a model that generalizes well to new data.
What is testing data in machine learning聽聽
The process of model evaluation in both supervised and unsupervised ML involves measuring the performance of the model on a dataset that was not used during training. In both supervised and unsupervised ML, the role of test data is to evaluate the performance of the model. This provides an unbiased estimate of the model鈥檚 ability to generalize to new data, which is essential for understanding its real-world performance.
The evaluation metrics provide a quantitative measure of how well the model is able to predict the output for new, unseen data. The choice of evaluation metrics depends on the specific problem and the nature of the data. For example, for binary classification models, accuracy, precision, recall, F1 score and area under receiver operating characteristic curve are commonly used, while for regression problems, mean squared error and explained variance are routine metrics. It鈥檚 also worth noting that these are not the only evaluation metrics available, and other metrics can be used depending on the problem at hand.

The choice of evaluation metrics for unsupervised ML algorithms can be more challenging compared to supervised learning. In clustering, for example, there is no ground truth to compare the clusters to. Metrics such as inertia and silhouette score are used to evaluate the quality of the clusters. Inertia (or sum of squared errors) calculates the sum of the squared distances of each point to its closest cluster center.
Silhouette score measures the quality of clustering by evaluating how similar each data point is to its own cluster compared to other clusters. In dimensionality reduction, the evaluation metrics depend on the specific problem but typically include explained variance or reconstruction error. For visualization techniques, the evaluation is based on the quality of the visualization, which is subjective and difficult to quantify.
It is challenging to find the right proportion for splitting the dataset. The optimal proportions for the training, validation and test sets can vary depending on the size of the dataset and the complexity of the ML problem. However, a common split is 70% for training, 15% for validation and 15% for testing. In some cases, an 80-20% split for training and testing is also used.
If there is not enough data available, a common solution is to use cross-validation techniques 鈥?for example, k-fold cross-validation. In k-fold cross-validation, the data is split into k folds, and the model is trained and evaluated k times, each time using a different fold as the test set and the remaining folds as the training set. The results are then averaged to obtain an estimate of the model's performance.聽
Written by Eleonóra Bassi



… [Trackback]
[…] Read More here on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Here you can find 87997 more Info on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More on on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More Info here on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Here you will find 58828 more Information on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] There you will find 3278 more Information on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More Information here to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Read More on to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Read More on to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] There you can find 51843 more Info on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Here you will find 58201 more Information to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] There you will find 75306 additional Info to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More here to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Read More Information here to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Read More here to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Here you can find 38922 more Info to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More to that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/academys/beginner/2310/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/academys/beginner/2310/ […]