Data protection in AI chatting: Does ChatGPT comply with GDPR standards?


In the 1950s, Alan Turing theorized that computers could interact with humans. As early as 1966, the first chatting — or chatbot — software, Eliza, emerged as a natural language processing (NLP) computer program invented by Massachusetts Institute of Technology computer scientist Joseph Weizenbaum.
Artificial intelligence (AI) chatting is a computer program that enables customers to engage via messaging, texts or speech using NLP and AI to read, understand, and automatically respond to customers’ queries and general questions without human intervention.
 works")
Over the years, new messaging applications appeared and continue to rise in popularity among businesses and consumers alike. From text-based chatbots, the technology developed into audio-input messaging applications such as Amazon Alexa and Apple’s Siri, which offer a conversational way to help refine responses and follow-up questions.
Through natural language understanding, machine learning and deep learning, today’s AI chatting can ascertain what the user is trying to accomplish, providing more accurate and relevant responses to queries instead of reacting to simple rule-based question models.
As time passes, AI chatbots become more proficient in interacting accurately by implementing deep learning and machine learning. The more an AI chatbot interacts with an individual or entity, the more refined and effective its responses become.
The latest breakthrough in AI chatting is ChatGPT (Chat Generative Pre-training Transformer), developed by Sam Altman’s OpenAI and launched in November 2022. Its popularity has risen quickly, recording over one million users in only five days, allowing them to talk to the AI about almost anything in different styles, tones and languages.
Importance of data protection in AI chatting
Modern AI chatting is no longer a rule-based model but employs modern natural language and machine learning techniques that use conversational data from multiple sources. A traditional rule-based model is a type of AI model that makes decisions based on a set of predefined rules rather than learning from data.
Such a model makes the conversation more realistic for the individual interacting with the chatbot, which is designed to learn from a chat that may contain personal data, but, for this reason, it may yield a security risk.
Users mostly don’t know how their sensitive personal identifying information is managed, used, stored or even shared. Online threats and vulnerabilities in AI chatting are significant security issues if an organization and its systems are compromised, the personal data is leaked, stolen and used for malicious purposes.
Therefore, problems of data storage and usage obtained from the communicating user arise along with the need for some standards to protect the customer.
Understanding data protection in AI Chatting
The nature of AI chatting is to process and analyze a large amount of data, including personal information, to produce relevant results. However, the use of big data seems to diverge from the concept of privacy; how can businesses harness the full potential of AI chatting while protecting privacy?
Indeed, before the full potential of AI chatting technology is unleashed, the data protection challenge must be addressed by regulating how personal data is used and stored, especially considering consumers’ and organizations’ different expectations and approaches.
To comply with privacy and data protection principles, businesses should limit the collection and retention of personal information, clearly state the purpose of data collection from the outset, and abide by that purpose.
Organizations should explain how they use customer data, who has access to it, how long they retain it and so forth. They should earn their consumers’ trust by providing a regulatory framework that protects their privacy rights and ensures their personal information is not taken and used for profit without their knowledge.
Types of data collected and processed by AI chatting
Data is crucial to building a proper conversation with an AI chatting tool, but what types of data are collected and processed by the chatbot? The more companies know about their customers, the better experience they can deliver.

Thus, AI chatbots collect a broad range of personal data, including full legal names, geo-location or addresses, account information, email addresses, phone numbers, personal preferences and feedback regarding the service.
This data is collected and processed for several reasons, including improving user experience and targeted advertising. Collected data is also used for training purposes to prepare the AI chatbot for future queries and to understand human language to respond to users’ questions accordingly.
A good data collection strategy is necessary to provide more accurate AI chatting support, which can help obtain better business results.
Potential risks and privacy concerns related to data protection in AI chatting
Being dependent on an internet connection, AI chatting is vulnerable to online hacks and other cyberattacks that could compromise users’ personal data privacy and security. Malicious chatbots can be found simulating human behavior and conversations to trick users into revealing their personal data, including financial information.
Because AI chatting is designed to better understand users’ personalities and interests, it is prone to identity-based crimes. The more thieves know about a person and their preferences, the easier it is to impersonate them.
Data protection should include tools and policies to restrict data access. Companies should comply with regulations to ensure users’ privacy requests are strictly observed, with measures taken to protect private user information, preventing data breaches.
Other than data protection, users can take further individual actions to protect themselves, such as installing virus protection in their computers, using firewalls, and using lengthy and complex passwords. It’s crucial to be up-to-date on best practices for staying safe online.
The main privacy concern in AI chatting data protection is the collection of a wide range of personal data for the chatbot to be effective, which collides with the European General Data Protection Regulation (GDPR) principle of data minimization and purpose limitation.
GDPR standards and requirements
GDPR was approved and launched in the European Union in May 2018, providing official standards for data privacy regulations and setting an exemplary model for other states. GDPR was conceived to protect people’s fundamental rights to privacy and freedom, and safeguard personal data from malicious use. GDPR is enforced only in companies based in the EU or services processing EU citizens’ data.
As AI chatbots have access to users’ personal identifying information and personal details, they will necessarily fall under the GDPR legislation. Therefore, a business should only request the minimum requirement of personal data and use it for stated purposes, such as sending information about its services and products.

How does GDPR apply to AI chatbots?
Like other technology, AI chatting tools are banned from collecting and storing sensitive personal data such as ethnicity, religion and health, and must process data transparently.
The GDPR grants individuals the right to request that their personal data be erased, as well as the right to object to the use of their personal data. Companies must obtain explicit consent from consumers before using their personal data in chatbot interactions. They must clearly explain how and why the data will be used, per GDPR.
Collecting and using consumers’ personal data for anything not agreed upon in compliance with GDPR guidelines could mean the breaching company incurs a hefty fine of up to €20 million or four percent of its global turnover.
The GDPR requires that companies take appropriate measures to authenticate personal data and ensure its secure usage. While biometric data is not mandated, robust authentication processes should be implemented to protect the confidentiality and integrity of personal information.
It is important to note that using photographs of the user may not be sufficient to meet GDPR standards for authentication. End-to-end encryption is also a requirement in AI chatting, which may help prevent data breaches and fraud attempts more effectively.
Potential consequences of non-compliance with GDPR
The GDPR and other data protection regulations worldwide demand that companies take adequate privacy and security measures to protect people’s data, such as pseudonymization and encrypting personal data.
Most GDPR fines have been related to violations of data processing principles stating that personal data must be processed lawfully, fairly and transparently, and collected only for legitimate purposes. Furthermore, the personal data must be adequate, relevant and limited to what is necessary — and stored only as long as needed. The data can only be processed if the user has given consent.
Non-compliance with GDPR may result in severe penalties and fines for businesses. After Brexit, the United Kingdom and the EU have set the following penalties:

However, not all GDPR infringements lead to data protection fines. A range of other actions may be taken, including:
- Issuing warnings and reprimands.
- Imposing a temporary or permanent ban on data processing.
- Ordering the rectification, restriction or erasure of data.
- Suspending data transfers to third countries.
That said, fines are just one of the possible measures that can be taken. They are typically reserved for more severe violations of the GDPR, such as failure to obtain consent for data processing or for processing sensitive personal data without appropriate safeguards.
Compliance with GDPR by ChatGPT
The OpenAI data privacy policy concerning ChatGPT details the company’s efforts to comply with the California Consumer Privacy Act. However, details are quite thin regarding international laws, including GDPR. The data privacy policy provides general information regarding personal data usage, data retention policies and third-party access.
Channels to communicate with dedicated teams for specific requests concerning a user’s personal data treatment are also provided. However, there are areas where OpenAI’s data privacy policy for ChatGPT could have challenges complying with GDPR.
Previous sections have highlighted the aspects of data privacy emphasized by GDPR, which must be adhered to by entities that collect user data. Organizations utilizing these solutions to process customer data and generate insights via ChatGPT should consider these implications.
These are the areas where ChatGPT could have challenges adhering to GDPR standards as it processes, stores and shares users’ personal data.
Data minimization
The ChatGPT model was trained using reinforcement learning from human feedback, a technique that involves training the model through human interactions and reinforcement. However, for the supervised training to happen, the AI would have been fed data from across the web. Supervised training involves training a model using labeled data where the model is taught to map inputs to desired outputs.
GDPR mandates that solutions using users’ personal data must stick to a minimal amount of information that is sourced lawfully, fairly and transparently. ChatGPT would have required several billion data points from the web to train and improve the AI engine.
Any such sourcing of information to train the AI engine stands in breach of GDPR. The OpenAI blogs haven’t been explicit about data sources, particularly where users’ personal information was used to train the AI. However, the process of training ChatGPT is described in detail on the OpenAI blog.

Purpose limitation
As per GDPR, purpose limitation is an essential guideline where the solution using personal data uses it only for specific, explicit and legitimate purposes, not for purposes beyond the specified ones. However, with ChatGPT, the data it processes is being used for machine learning purposes, making it more accurate over time.
As a result, organizations using ChatGPT to tap into its intelligence while still processing users’ personal information must clearly state and agree that their data will be used for further training ChatGPT.
Explainability
The GDPR also emphasizes the need for automated decision-making programs to be able to provide explanations for their decisions. Although ChatGPT can provide valuable insights on various topics, organizations using the AI engine must develop capabilities explaining ChatGPT’s insights to comply with GDPR.
Segregation of data
As per GDPR, technical and organizational measures must be in place to ensure data sources aren’t merged. This is particularly critical when data is shared with third parties.
ChatGPT can aggregate information across data sources to provide inferences and insights. If an organization wants to decide on a customer based on their data, and ChatGPT’s suggestions include information accrued from other customers’ data attributes, that could be a breach of GDPR. If this knowledge is shared with third parties, that could be non-compliant with GDPR too.
Third-party data sharing
GDPR mandates that users must always be informed of third-party data sharing and know precisely what the data will be used for, particularly if it will be monetized. User consent must be sought and freely given for such data-sharing practices. However, OpenAI’s data policy states the following.
“In certain circumstances we may provide your personal information to third parties without further notice to you, unless required by the law.”
There are no further details on how data sharing with third parties will be brought in line with GDPR requirements on its policy. However, there are details of the type of third parties OpenAI could share users’ data with. They are as follows:
- Vendors and service providers covering any third parties that assist OpenAI with its business operations needs.
- Business transfers, where OpenAI is involved in strategic transactions, user data will need to be shared with the counterparty organization.
- Legal requirements where OpenAI is legally bound to share user data in the interest of national security or other urgent situations.
- Affiliates who are entities that have common control with OpenAI and are mandated to be following the OpenAI data privacy policy.
Data collection and processing by ChatGPT
ChatGPT collects a broad range of information. The different user data attributes are described in the OpenAI data privacy policy. This is the data collected if users create an account to use the service:
- Account information attributes such as name, contact information, account credentials, payment card information and transaction history.
- User content such as file uploads or feedback provided by the user to the services OpenAI offers.
- Communication information attributes such as name, contact information and the content of the message that the user sends when they want to communicate with OpenAI.
- Social media information like Instagram, Facebook, Medium, Twitter, YouTube and LinkedIn accounts that the user chooses to share with OpenAI.
Aside from the above, ChatGPT and OpenAI automatically receive data from those who use their services. Those data attributes are as follows:
- Log data on how the user interacted with the ChatGPT/OpenAI website. This also includes details on IP address, browser details, and the date and time of specific requests placed on the website.
- Usage data on the type of content a user views and engages with, the actions the user takes, time zones and devices used.
- Cookies are used to operate and offer services. However, users have the choice to accept or reject cookies. Rejecting cookies may result in incomplete functionalities from OpenAI. Data gathered using cookies will be analyzed using analytics products to customize the user experience.
Despite collecting all this information, OpenAI privacy policies offer users the right to request the deletion of their personal data. Nonetheless, it remains to be seen how effective this requirement will be in the era of machine learning.
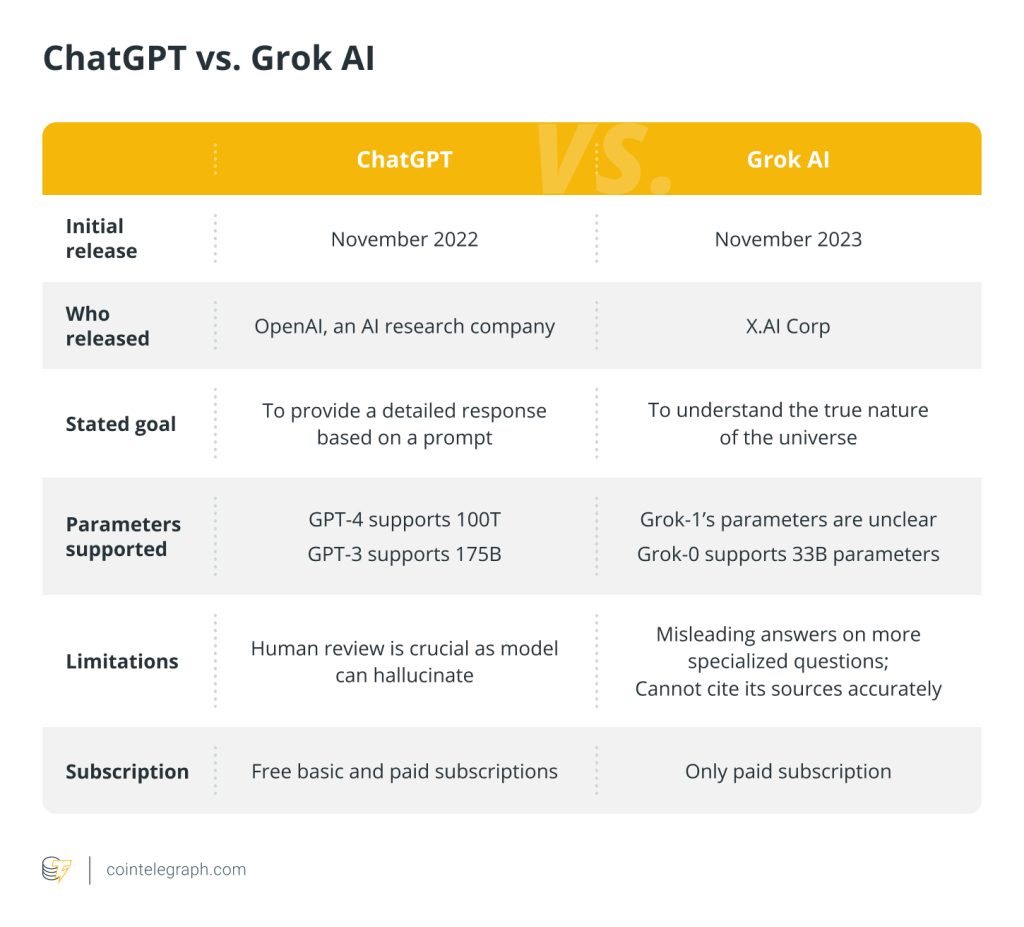
Data protection measures: ChatGPT vs. BERT
BERT and ChatGPT are both popular AI language models developed by Google and OpenAI, respectively. As a bidirectional model, bidirectional encoder representations from transformers (BERT) considers both the left and right contexts of a word while constructing its representation.
It is trained using a masked language modeling technique. The model must predict the original word in sentences where random words have been substituted with unique tokens. BERT is frequently used for tasks including named entity identification, sentence categorization and question answering.

Conversely, ChatGPT is a generative model created using an unsupervised learning process. It is initially trained on a sizable corpus of text before being honed for various downstream purposes. Because of its reputation for producing high-quality content, ChatGPT is advantageous for tasks like text completion, summarization and language translation.

Both ChatGPT and BERT take several measures to protect user data and ensure the security and privacy of their users. Here’s a comparison of the data protection measures taken by ChatGPT and BERT:

It’s crucial to remember that the specific data protection methods used by ChatGPT and BERT may vary depending on the application’s requirements and the use case at hand. As a result, the steps followed may change depending on the implementation. Both ChatGPT and BERT take steps to preserve users’ data security and privacy.
User rights and consent
Under GDPR, users have several rights related to data protection, including the right to access, rectify and erase their data, and the right to restrict or object to the processing of their data. Users also have the right to transfer their data to another data controller and receive it in a machine-readable format. These rights are supposed to give users more control over their data and guarantee that it is handled openly and legally.
To ensure that users are aware of and may exercise their rights, ChatGPT takes several precautions. For instance, ChatGPT’s privacy policy specifies how users can exercise their user rights concerning data protection and outlines these rights in detail. Also, individuals may request access to their personal data from ChatGPT, which they can then alter or remove as necessary.
ChatGPT may employ many techniques to ascertain and record user consent for data collection and processing. For instance, when a user interacts with the model for the first time, they can be given a brief explanation of the data that will be gathered and its intended use. The user may then be prompted to give clear permission for collecting and processing their data, which can be transparently documented.
Future considerations
ChatGPT is potentially subject to GDPR implications in several areas. The banning of the software in Italy indicates that the future could be bumpy for ChatGPT, particularly in Europe, where data protection laws are much more stringent than in the United States. For instance, data protection laws in the U.S. vary by state, with no federal data protection law providing the same level of regulation as the GDPR.
There is a need for greater transparency from the OpenAI team regarding the data used to stay compliant with data protection laws. They must take the same transparent approach in collecting, storing and sharing user data. More importantly, regulators are keen on the “explainability” of ChatGPT’s outputs.
As the application of the tool moves into critical fields like healthcare and financial services, OpenAI must work with regulators to develop the guardrails needed to protect consumers and treat their personal data with robust controls.
Written by: Emi Lacapra, Arunkumar Krishnakumar and Guneet Kaur


… [Trackback]
[…] Here you will find 24951 additional Info on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Here you will find 25813 more Info on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Here you can find 42561 more Information to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Find More to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More on on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Here you can find 2343 more Info to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More on to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Find More on to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More on to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Here you can find 20706 more Information on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] There you will find 87557 more Information to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Read More to that Topic: x.superex.com/academys/beginner/2224/ […]
… [Trackback]
[…] Find More here to that Topic: x.superex.com/academys/beginner/2224/ […]