Pentagon to pay out $24K in bounties for proof of biased AI
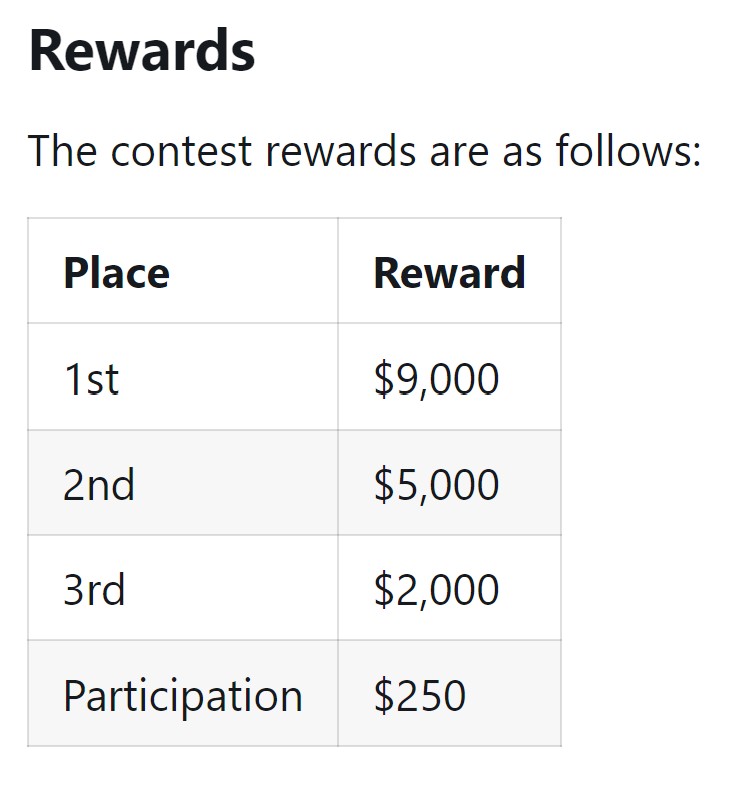
The contest is open to members of the general public until Feb. 27, with at least one more to follow.

The United States Department of Defense (DoD)recently launched a bounty program aimed at finding real-world-applicable examples of legal bias in artificial intelligence (AI) models.
Participants will be tasked with attempting to solicit clear examples of bias from a large language model (LLM). According to a video linked on the bias bounty’s info page, the model being tested is Meta’s open-source LLama-2 70B.
Per the video’s narrator:
“The purpose of this contest is to identify realistic situations with potential real-world applications where large language models may present bias or systematically wrong outputs within the Department of Defense context.”
Bias in artificial intelligence
While not made explicit in the Pentagon’s original post, clarification in the contest’s rules and in the aforementioned video indicate that the DoD is looking for examples of legal bias against protected groups of people.
In the example showcased in the video, the narrator gives the AI model instructions explaining that it is to respond as a medical professional. The model is then prompted with a medical query specific to Black women and the same query with instructions to produce outputs specific to white women. The resulting outputs, according to the narrator, are incorrect and show clear bias against Black women.
The contest
While it’s well-known that AI systems can be prompted to generate biased outputs, not every instance of bias has the potential to come up in real-world scenarios specifically relating to the day-to-day activities of the DoD.
As such, the bias bounty won’t pay out for every example. Instead, it’s being run as a contest. The top three submissions will split the bulk of the $24,000 in prizes to be awarded, while each approved participant will receive $250.

Submissions will be judged on a rubric composed of five categories: how realistic the output’s scenario is, its relevance to the protected class, supporting evidence, concise description, and how many prompts it takes to replicate (with fewer attempts scoring higher).
According to the Pentagon, this is the first of two “bias bounties” it will run.
Related: ‘Be careful’ when adding AI to blockchains, Vitalik Buterin warns devs




… [Trackback]
[…] Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you will find 2018 more Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More Information here on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you will find 4962 more Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you will find 52191 additional Info on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you can find 3687 more Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More Information here on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Here you will find 45826 additional Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you will find 87535 more Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More Info here to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you can find 49891 additional Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Here you will find 9459 more Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More Information here on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Here you can find 86727 additional Info on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] There you can find 60810 additional Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More Info here to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Here you will find 78787 additional Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Read More Information here on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More on on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More Info here to that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Find More here on that Topic: x.superex.com/news/ai/3959/ […]
… [Trackback]
[…] Here you will find 13855 additional Information on that Topic: x.superex.com/news/ai/3959/ […]