OpenAI eyes partnership with CNN, Fox and Time to secure news content licensing
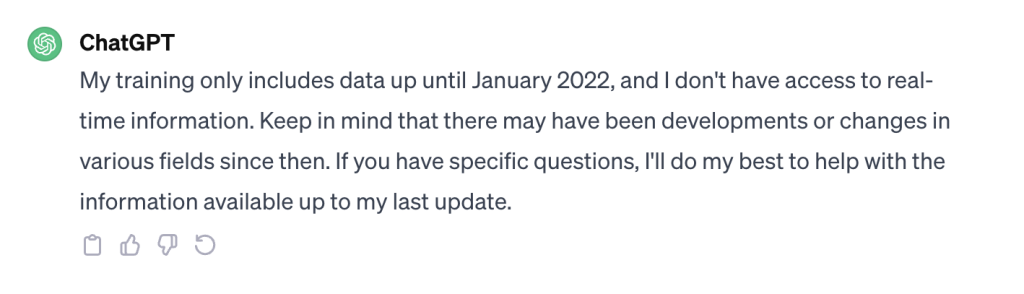
OpenAI has opened conversations with major news telecasters including CNN, Fox and Time about licensing their work for AI training to avoid copyright violations.

The artificial intelligence (AI) developer OpenAI is in discussions with major new corporations CNN, Fox Corp. and Time to license their news content, according to a report from Bloomberg.
OpenAI is reportedly seeking to make deals with the media giants producing news, video and other types of digital media content to help make its AI chatbots more accurate and up to date.
For example, OpenAI said it is discussing licensing articles from CNN to train ChatGPT and feature its content in OpenAI products. Both CNN and Fox are reportedly discussing licensing text, video, and imagery.
On Jan.9 Fox Corp announced the launch of a Polygon-based blockchain platform to help verify AI firms’ use of its content.
Jessica Sibley, the CEO of Time, released a statement saying it is in discussions with OpenAI and that “we are optimistic about reaching an agreement that reflects the fair value of our content.”
At the time of writing, OpenAI’s free, publicly available AI chatbot ChatGPT-3.5 is only equipped with training data until January 2022.

However, in September 2023, OpenAI announced that its premium and enterprise models running ChatGPT-4 can now browse the internet and are no longer capped to the training timeline.
OpenAI’s initiative to create licensing deals with media companies would essentially save it from headaches down the road regarding copyright violations.
Related: Michigan university to let AI participate in classes, choose major, earn degree
This comes as OpenAI faces multiple lawsuits regarding alleged copyright infringement of content that it used to train its AI models.
The most significant being a lawsuit filed by The New York Times on Dec. 27 alleging that OpenAI’s use of its content in training is “not fair use by any measure” and that the outcome of this usage threatens its journalistic work.
A week later, another lawsuit was filed against OpenAI by authors Nicholas Basbanes and Nicholas Gage, who argued that copyright owners should be compensated for using their work in AI training.
On Jan. 9, OpenAI officially responded to the NYT lawsuit allegations, calling it “without merit” and stating that it talks with media organizations about collaborations and partnerships for content licensing and AI integration.




… [Trackback]
[…] Read More on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Find More Info here on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More on to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More Info here to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More Information here to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More here to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Information on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Find More on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Find More Information here to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Find More Info here on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Here you will find 64052 more Info to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More Info here on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] There you will find 34333 more Information to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] There you can find 52713 additional Info to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Info on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More Information here on that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Info to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Read More Information here to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Information to that Topic: x.superex.com/news/ai/2282/ […]
… [Trackback]
[…] Find More Info here on that Topic: x.superex.com/news/ai/2282/ […]